常用组件示例-QueryRecord
在编排平台现有的 300 多个组件中,QueryRecord 比较常用的。在大多数情况下,如果了解 SQL 的基础知识,则使用起来非常简单,它可以用于许多不同的场景。
一、组件功能
简单来说,QueryRecord 能让你像处理数据库表一样处理每个 FlowFile,并对该表运行 SQL 查询,结果输出为 FlowFile 。
该组件使用记录读取器和记录写入器,这意味着我们可以隐式地将数据从一种格式转换为另一种格式。例如,我们可以使用 JSON 读取器和 Avro 写入器来读取输入的 JSON 并将结果写入为 Avro 。
二、使用场景
将流文件按不同要求拆分成多个
改变数据中的字段名称
筛选出需要的记录或列
将多个列合并为一个新的列
为列设置默认值
几乎所有在数据库上执行的 SQL SELECT 语句,除了与其他表进行 JOIN ( JOIN 操作需要用其它组件处理)
包括但不限于以上场景,都能通过 QueryRecord 组件实现:
三、属性说明
1. 属性配置
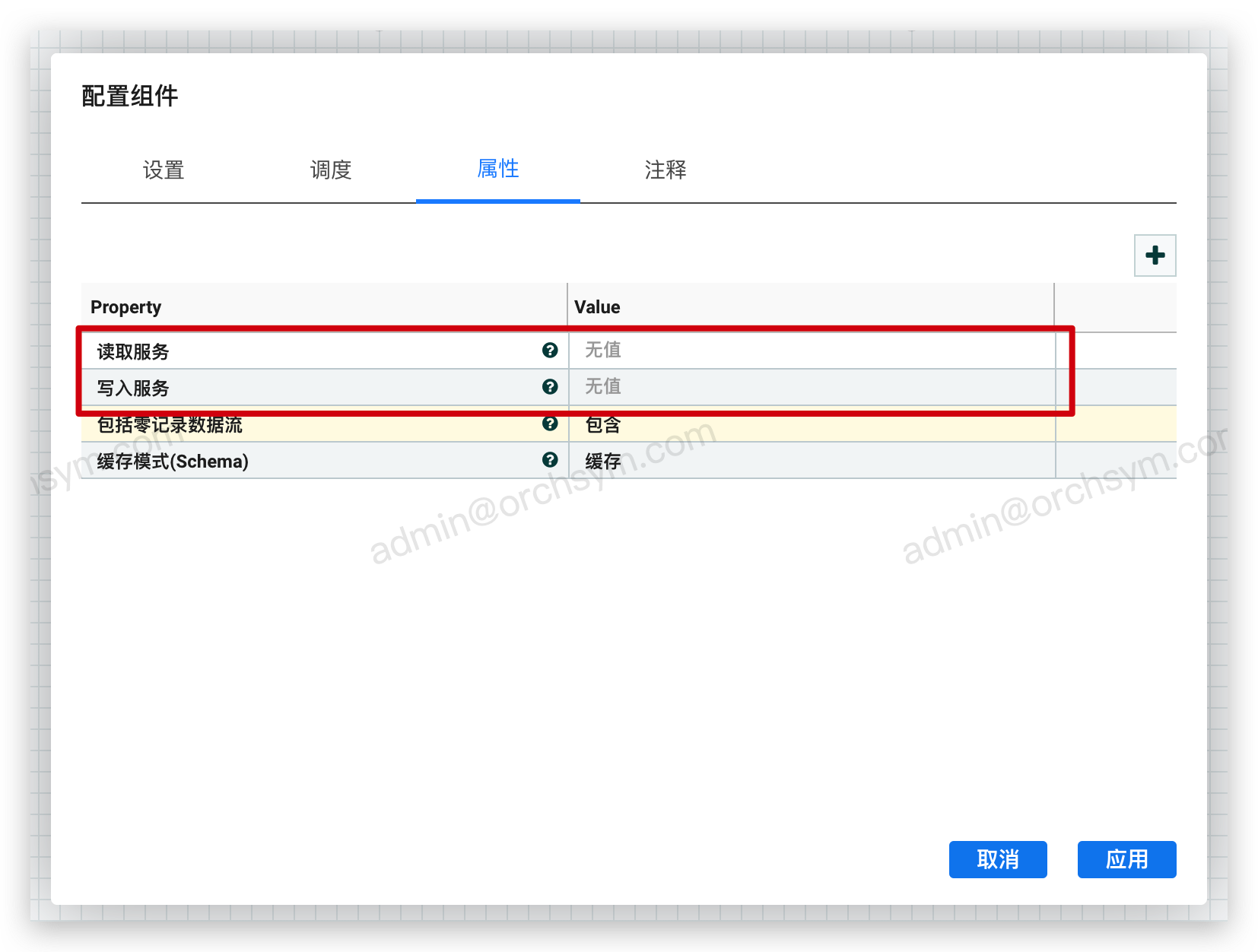
- 它是面向 Record 的组件,必须配置一个 Record Reader 和一个 Record Writer
- 包括零记录数据流:如果传入的 FlowFile 没有与指定的SQL查询匹配的数据,是否仍旧空的 FlowFile,默认输出
2. 新增属性
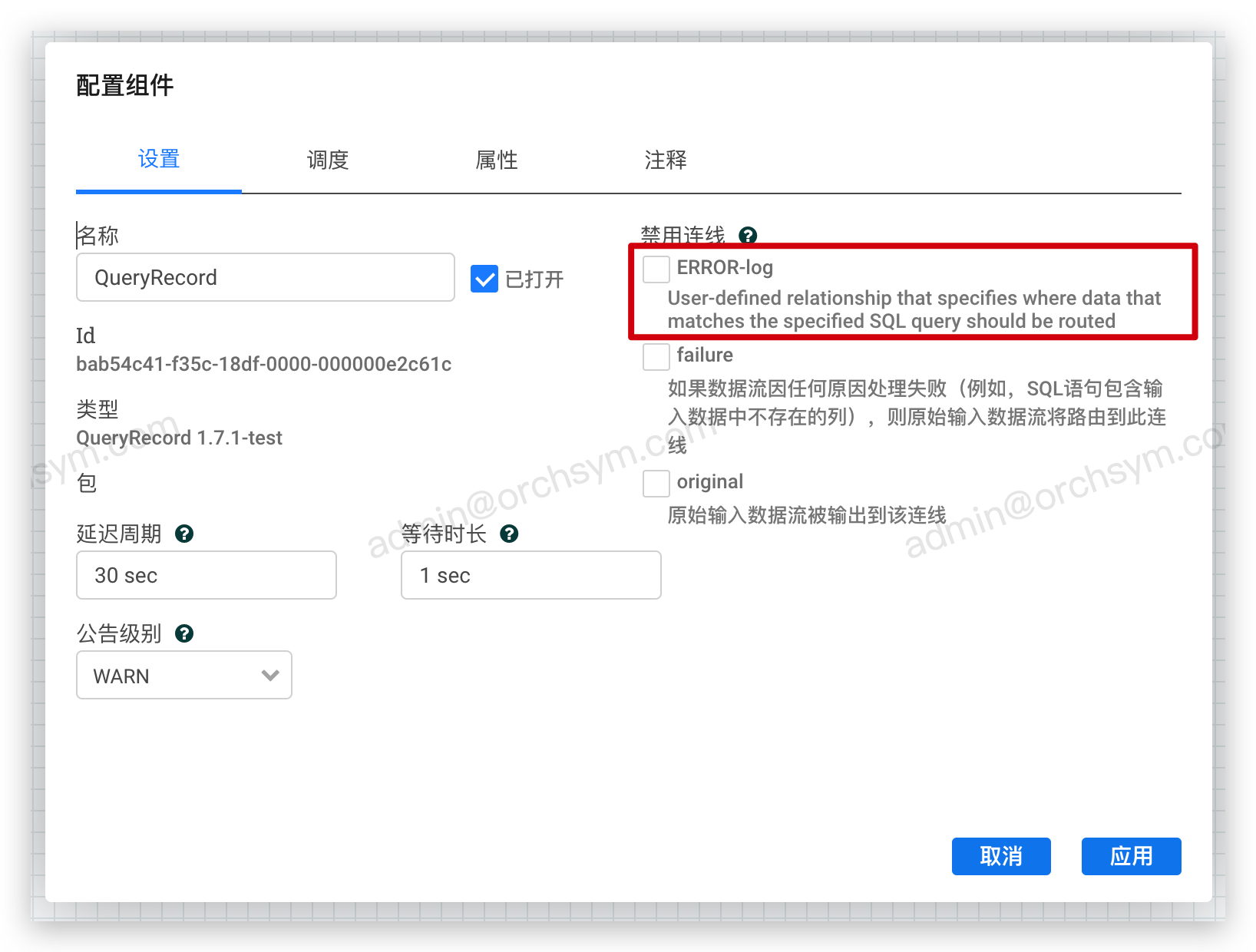
通过单击属性表右上角的“+”图标来添加一个或多个属性。当添加新属性时,属性的名称将成为组件的新连线。该属性的值成为针对数据运行的 SQL 查询,与 SQL 查询匹配的数据都将输出到该连线。
注意:SQL 查询的表名固定为 FLOWFILE (忽略大小写)
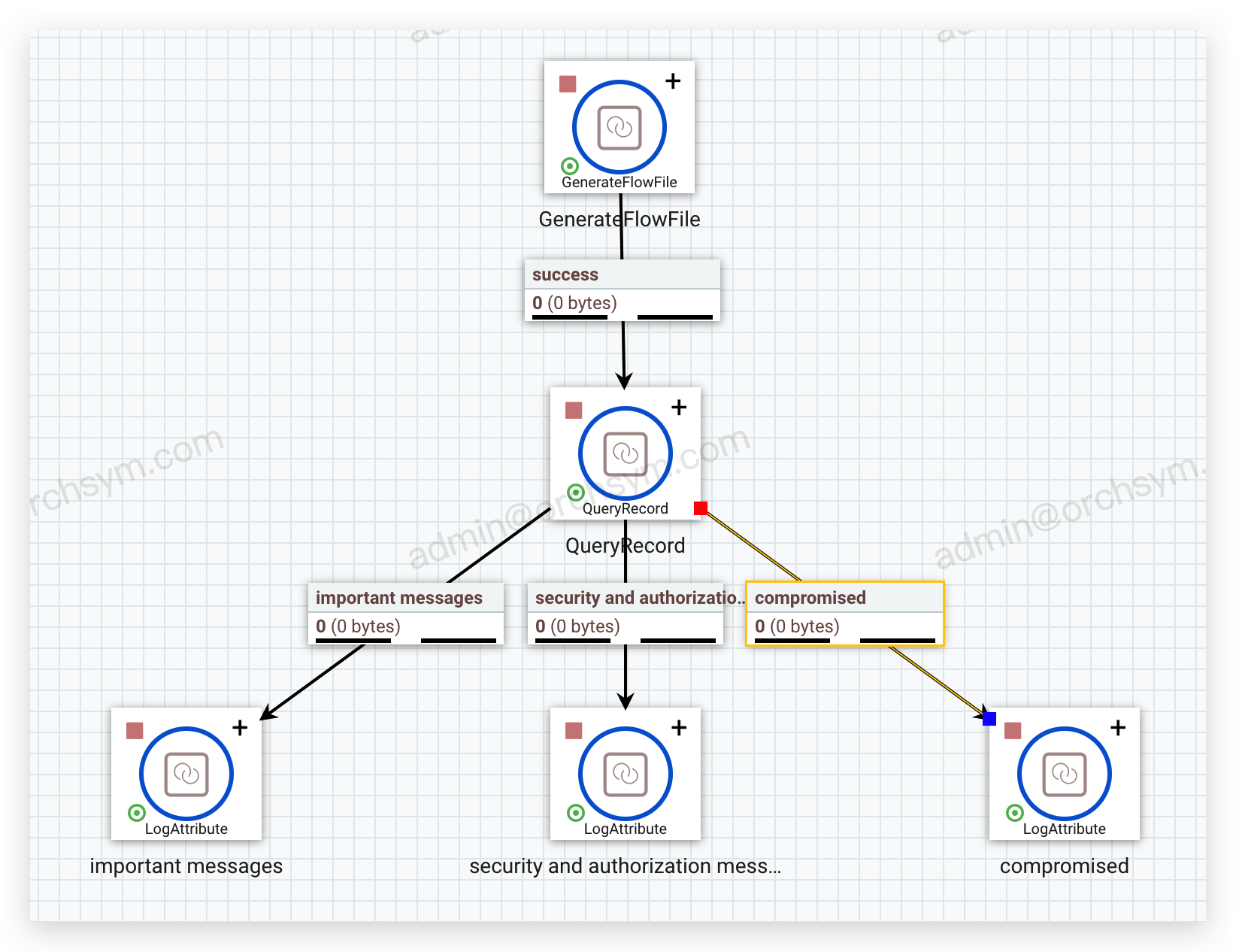
四、场景示例
以处理syslog数据为例,有原始数据如下:
<34>1 2023-06-06T14:23:32.123Z mymachine1.example.com cron - ID01 - Task 'update' started.
<38>1 2023-06-06T14:25:44.567Z mymachine2.example.com sshd - ID02 - User 'admin' logged in.
<30>1 2023-06-06T14:27:56.901Z mymachine3.example.com kernel - ID03 - USB device connected.
<34>1 2023-06-06T14:30:15.345Z mymachine1.example.com cron - ID04 - Task 'update' completed.
<28>1 2023-06-06T14:32:28.789Z mymachine4.example.com ftpd - ID05 - File 'report.txt' uploaded.
<34>1 2023-06-06T14:33:39.234Z mymachine2.example.com cron - ID06 - Task 'clean' started.
<38>1 2023-06-06T14:34:50.678Z mymachine1.example.com sshd - ID07 - User 'guest' logged out.
<30>1 2023-06-06T14:35:59.123Z mymachine3.example.com kernel - ID08 - USB device disconnected.
<34>1 2023-06-06T14:36:11.567Z mymachine2.example.com cron - ID09 - Task 'clean' completed.
<28>1 2023-06-06T14:37:22.901Z mymachine4.example.com ftpd - ID10 - File 'data.csv' downloaded.
1. 筛选出需要的行
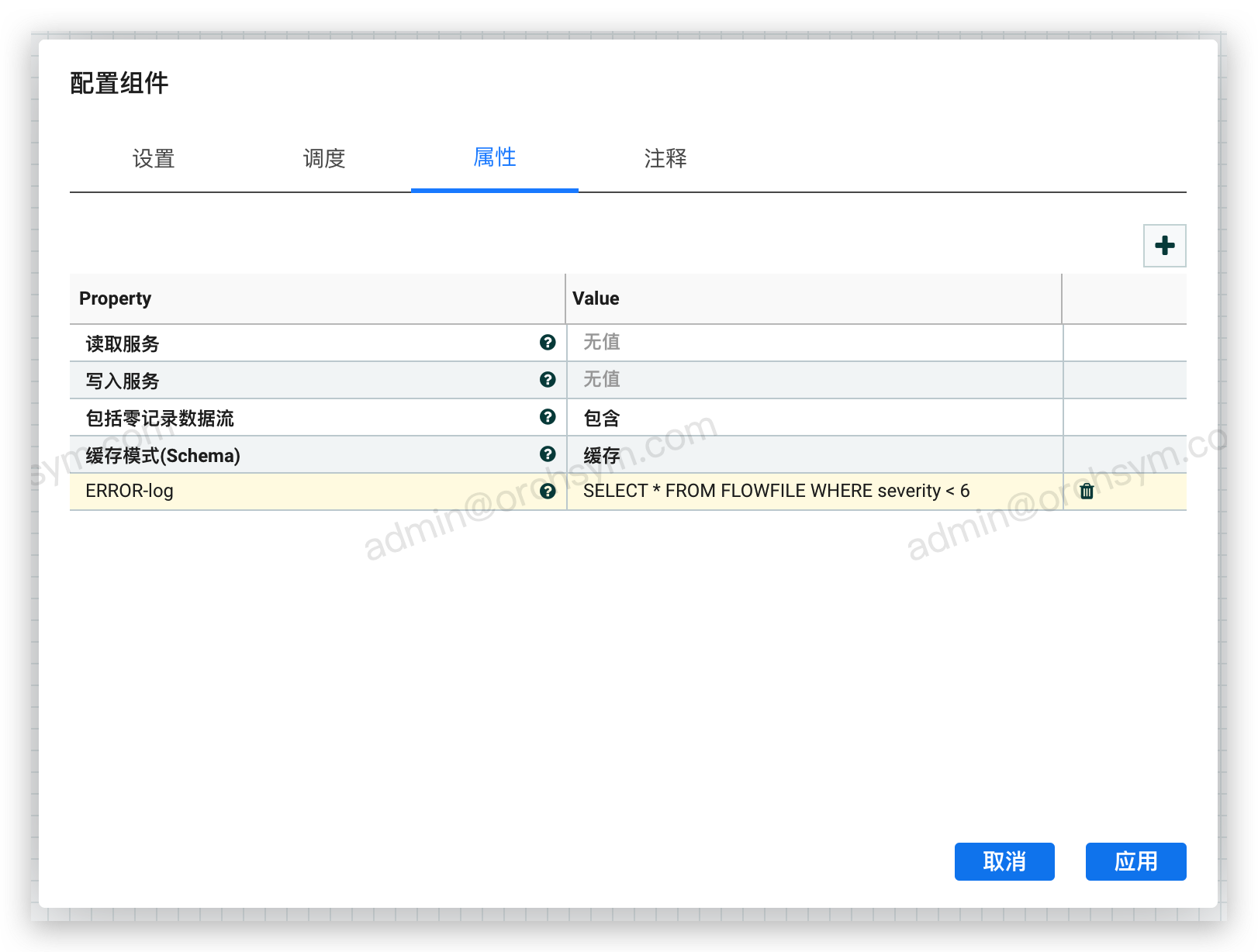
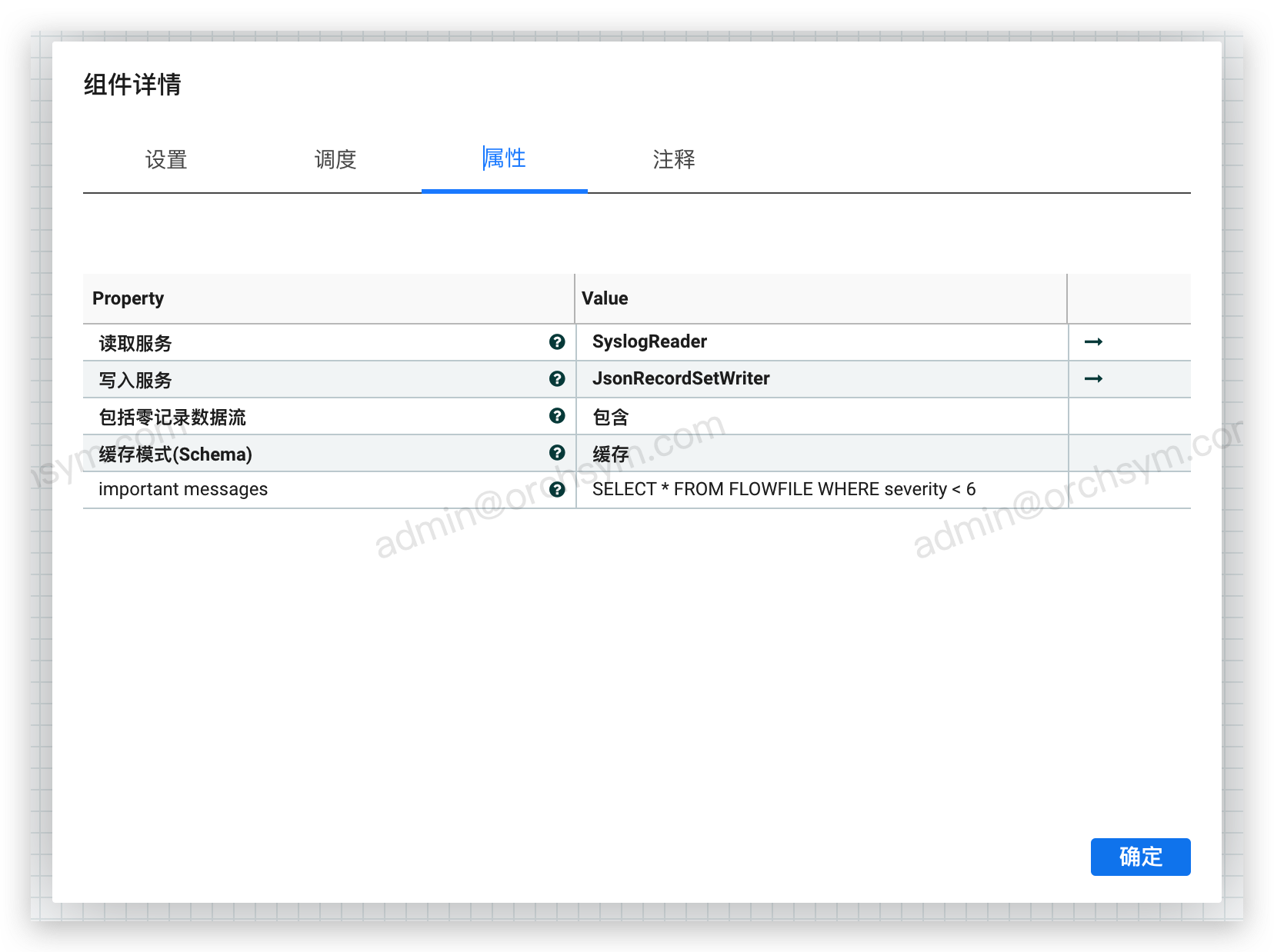
假如只需要关心 severity 6以下的数据,将该满足该条件的数据定义为 important messages,
SELECT * FROM FLOWFILE WHERE severity < 6
如果不需要所有的列,只需要在 SELECT 后指定需要返回的列即可,用 * 表示返回所有列
在 QueryRecord 中配置示例如下:
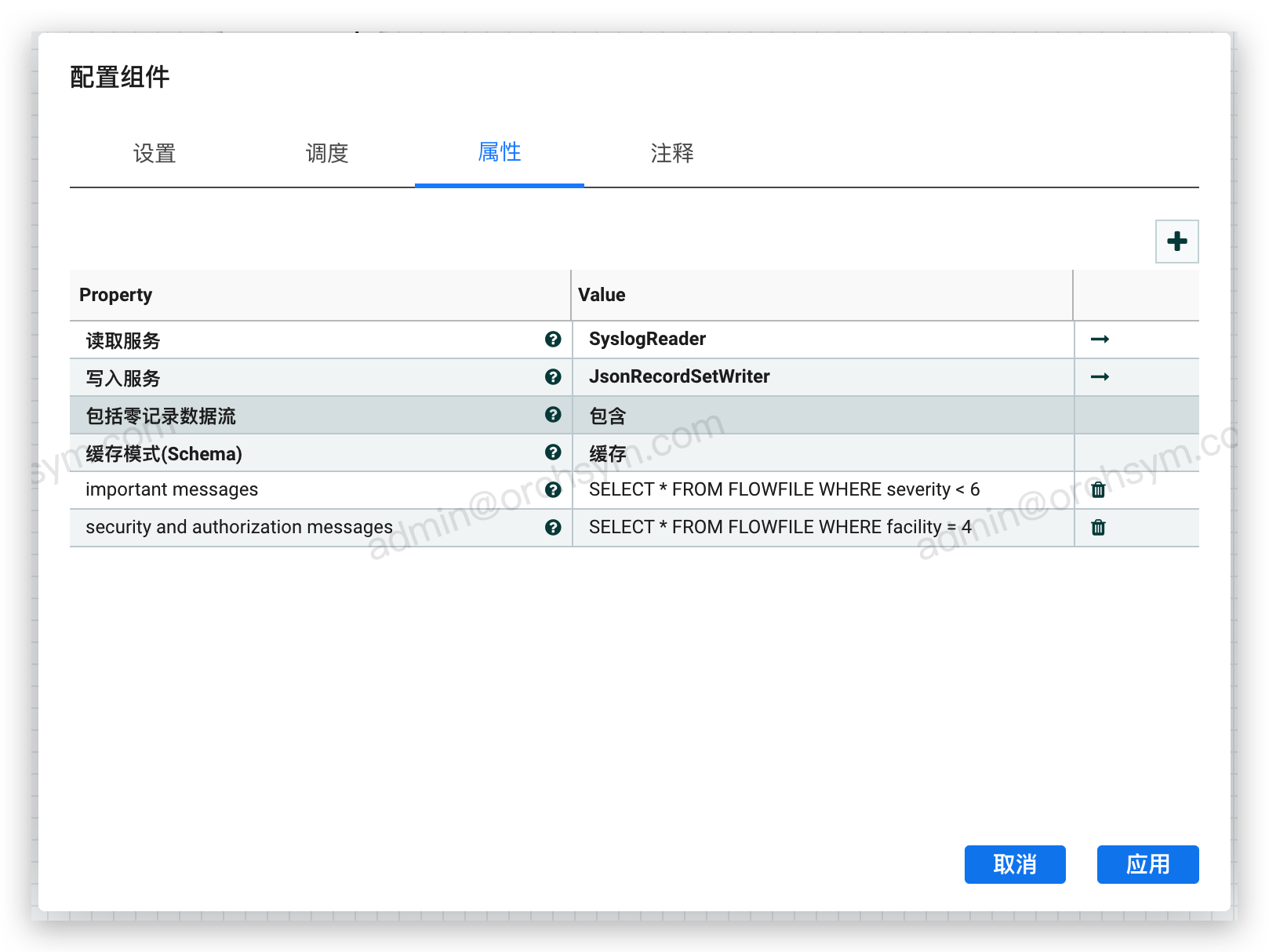
也可以注册多个 SQL SELECT 语句,对每个结果集都分出一个独立的流文件。例如,如果我们有另一个应用场景,比如在同样的 Syslog 数据中,我们想要将安全/授权信息(facility 值为4)相关的日志记录推送到 Kafka;可以使用一个 QueryRecord 组件同时完成上面的这些查询,然后根据使用场景处理每个流文件。如果数据有新的应用场景出现,只需要添加另一个查询来分离出新的流文件:
2. 筛选出需要的列
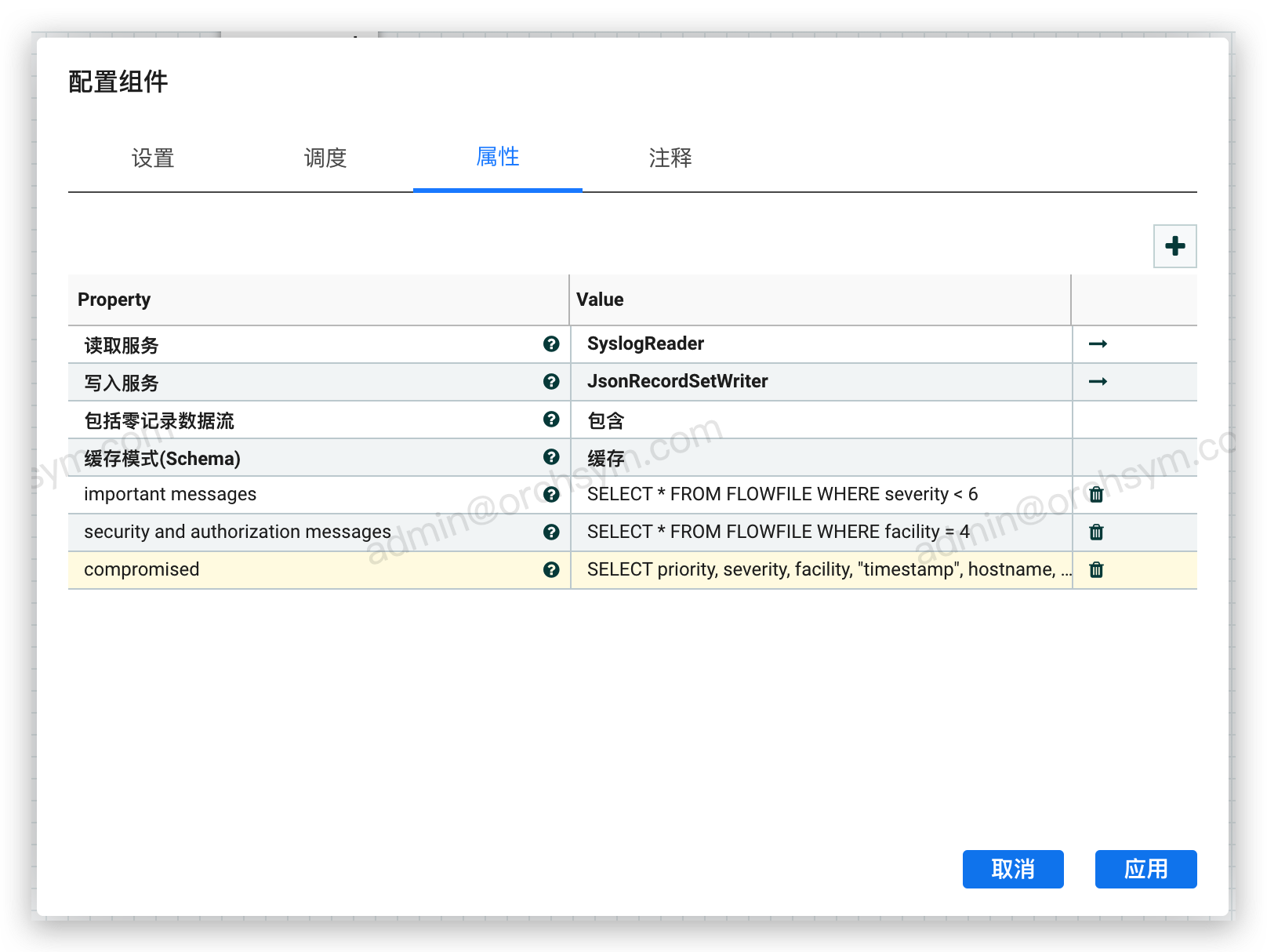
我们可以使用SQL将流文件内容视为数据库表格,就可以很容易地过滤掉我们不关心的列。例如,现在有一个数据流,需要所有与主机名compromised-server.mydomain.com有关的消息,不想要versions字段:
SELECT priority, severity, facility, "timestamp", hostname, body
FROM FLOWFILE
WHERE hostname = 'compromised-server.mydomain.com'
这里需要注意两点:
- 在SQL中,timestamp是一个保留关键字,所以需要用双引号引起来,以表明它是一个列名,而不是一个关键字。
- 其次,注意引用主机名时,它是一个字符串常量,所以需要使用单引号。字符串常量用单引号引起来,实体名用双引号引起来。
将这个查询命名为“compromised”:
3. 合并多个列
SQL还提供了在SELECT子句中将多个列合并为一个列的能力。例如,可以将hostname和timestamp字段合并为一个可能用作唯一键的字段:
SELECT "timestamp" || '-' || hostname AS key, priority, severity,
facility, "timestamp", hostname, body
FROM FLOWFILE
通过”||“来将字段合并
也可以使用一些SQL函数,例如,COALESCE 函数来获取第一个非空值:
SELECT COALESCE("timestamp", hostname, body) AS my_field, priority,
severity, facility, "timestamp", hostname, body
FROM FLOWFILE
4. 为列提供默认值
还可以使用 COALESCE 函数为特定列提供默认值。因为 COALESCE 返回第一个非空值,可以将当前的(可能为空)值与默认值合并:
SELECT priority, severity, facility, "timestamp",
COALESCE(hostname, 'unknown-host') AS hostname,
body
FROM FLOWFILE
还可以将值默设为其他一些现有字段:
SELECT priority, severity, facility, "timestamp",
COALESCE(hostname, priority, 'unknown-host') AS hostname,
body
FROM FLOWFILE
hostname 为空时,将 priority 的值作为 hostname 返回;如果 hostname 和 priority 都为空,则返回 ”unknown-host“
5. 复杂数据结构查询
上面几个示例介绍了如何使用 QueryRecord 查询 syslog 数据。这是一个简单、直观的示例,因为数据是结构化的。可以非常清晰地映射到数据库表结构,因为数据中的每个字段都是一个标量值。
但是,如果需要在更加复杂的数据上使用 SQL,比如嵌套的 JSON数据该如何实现查询?假设数据下面这种结构:
[
{
"name": "白山云",
"details": {
"address": {
"street": "望京",
"city": "北京",
"country": "中国"
},
},
"links": {
"name": "Orchsym",
"url": "https://www.baishan.com/pages/products/orchsym-iPaaS/"
}
},
{
"name": "白山云",
"details": {
"address": {
"street": "贵阳",
"city": "贵州",
"country": "中国"
},
},
"links": {
"name": "SD-WAN",
"url": "https://www.baishan.com/pages/products/SD-WAN/"
}
},
{
"name": "白山云",
"details": {
"address": {
"street": "厦门",
"city": "福建",
"country": "中国"
},
},
"links": {
"name": "CDN",
"url": "https://www.baishan.com/pages/products/DNS/"
}
},
{
"name": "白山云",
"details": {
"address": {
"street": "徐汇区",
"city": "上海",
"country": "中国"
},
},
"links": {
"name": "Access",
"url": "https://www.baishan.com/pages/products/application-trusted-access/"
}
}
]
在这种情况下,流文件生成的SQL表格有3个字段:name、details和links是有效的。但是,如果想筛选 city 在上海的产品线信息,就需要访问嵌入记录中的数据。
编排平台可以通过使用 RecordPath 函数来实现。所以,如果只想筛选 city 在上海的产品线信息,可以使用下面的SQL进行查询:
SELECT *
FROM FLOWFILE
WHERE RPATH(published, '/details/address/city') = '上海'
查询结果为:
[
{
"name": "白山云",
"details": {
"address": {
"street": "徐汇区",
"city": "上海",
"country": "中国"
},
},
"links": {
"name": "Access",
"url": "https://www.baishan.com/pages/products/application-trusted-access/"
}
}
]
通过使用 RecordPath 可以深入到任意数量的层次结构层。只要是结构化数据,都可以使用 RecordPath 表达式。比如数据是 JSON、带结构的 Parquet、Avro、XML 或其他结构化数据格式,RecordPath 表达式都可以生效。
五、流程模板
下载后导入编排平台运行:
参见附件(请右键另存保存):QueryRecord