常用组件示例-ReplaceText
在大多数编排流程场景开发过程中,涉及流文件内容处理时都会用到ReplaceText组件。ReplaceText 处理文本数据时功能非常强大,但是需要注意,如果将超大流文件的全部内容加载到内存中,可能会耗尽JVM Heap,导致机器内存溢出。
一、组件功能
ReplaceText是面向流文件内容的组件,它提供了对流文件内容执行搜索和替换操作的能力。此外,它还可用于将文本追加和文本前置到流文件内容的每一行或整个流文件。
二、使用场景
正则表达式替换:手机号脱敏
文本前置和文本后置:JSON对象转数组
文字替换:替换流文件内容(检索匹配值)
始终替换:替换流文件内容(忽略匹配值选项)
表达式函数:正则捕获组使用表达式函数
包括但不限于以上场景,都能通过 ReplaceText 组件实现:
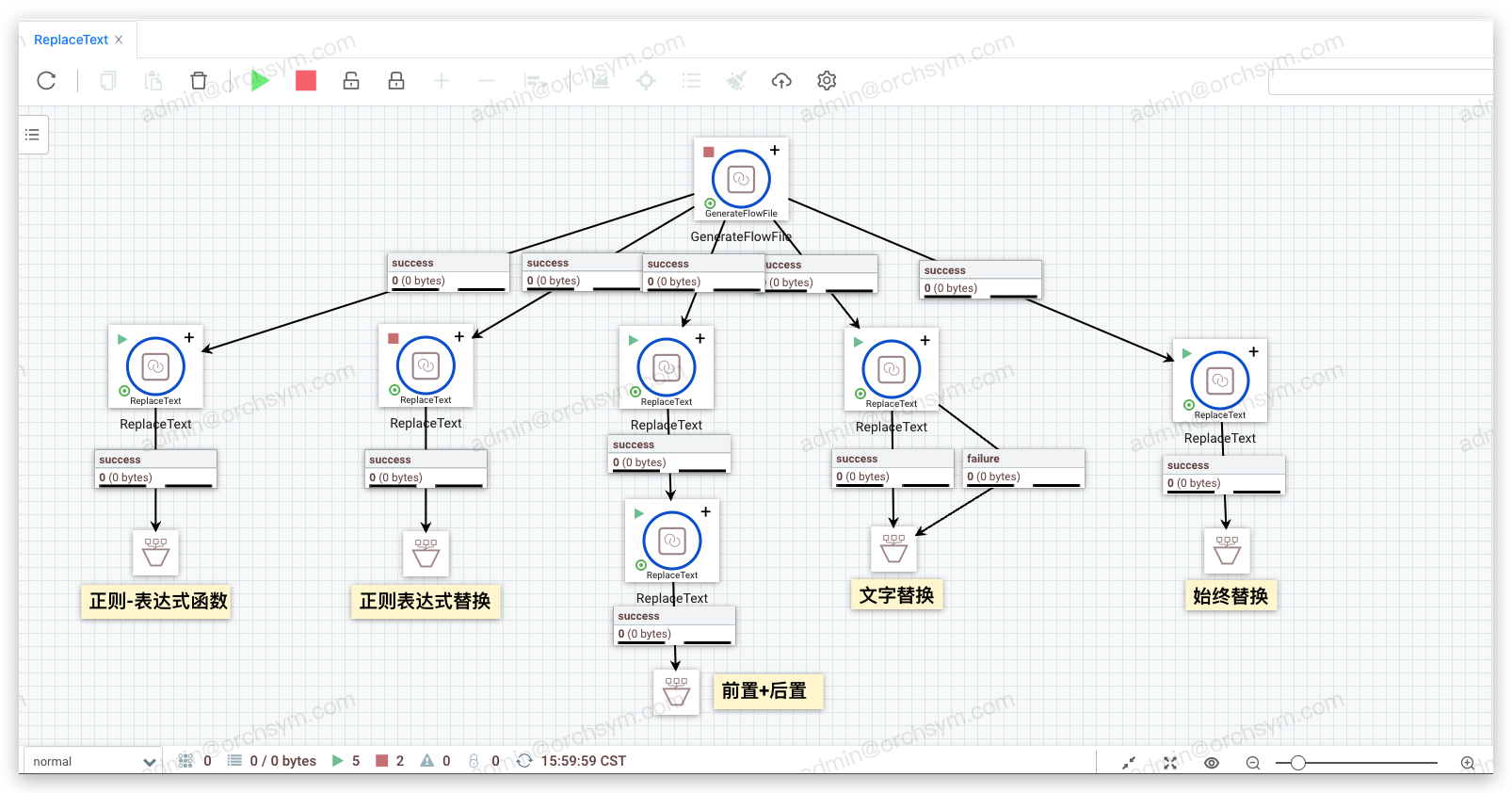
三、属性说明
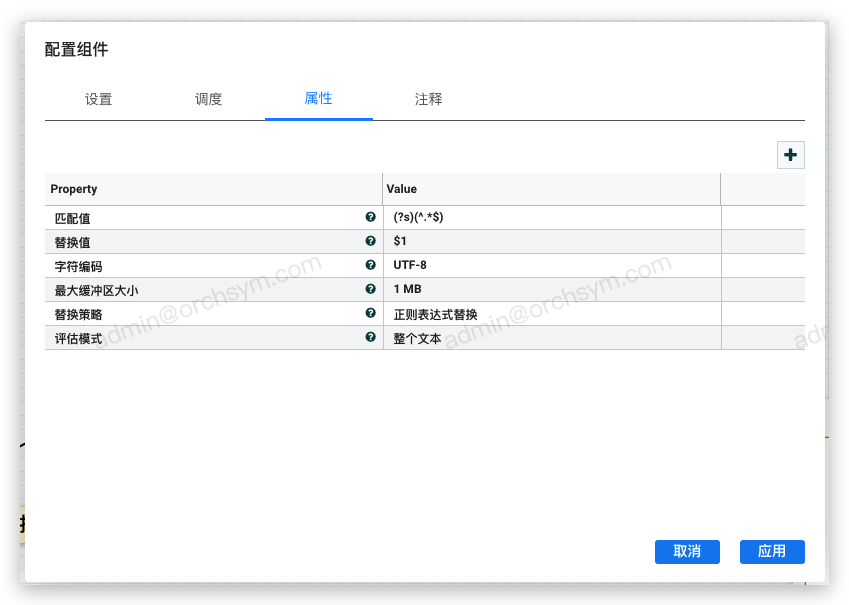
1. 属性配置
- 匹配值:用于检索和匹配流文件内容中要操作的部分数据,正则替换和文本替换2种替换策略时有效
- 替换值:用于替换掉匹配值的部分内容,或者用于指定文本前置、文本后置时的文本
- 最大缓冲区大小:设定内存大小,必须大于流文件内容,否则整个处理会失败
- 替换策略:指定替换值生效的策略
- 评估模式:指定如何替换文本,有逐行和整个文本两种方式
四、场景示例
以处理 JSON 数据为例,有原始数据如下:
{
"password": "123456",
"address": "北京市朝阳区",
"idCard": "360123202111111121",
"name": "张三",
"mobile": "15928826788",
"tel": "0571-28821110",
"job": {
"jobName": "研发",
"address": "北京市朝阳区东风德必园区K栋",
"company": "白山云",
"tel": "0571-28821110",
"position": [
"需求",
"开发",
"测试",
"上线"
],
"salary": 2000
},
"cardNo": "6227002020000101221",
"email": "zhangs12345@qq.com"
}
1. 正则表达式替换:手机号脱敏
11位的手机号:保留前3后4,中间部分用*号代替
(1)([3-9]{2})(\d{4})(\d{4})
Regex说明:
- (1):匹配数字1
- ([3-9]{2}):匹配2位数字,取值为3-9间的数字
- (\d{4}):匹配4位数字
- (\d{4}):匹配4位数字
在 ReplaceText 中配置示例如下:
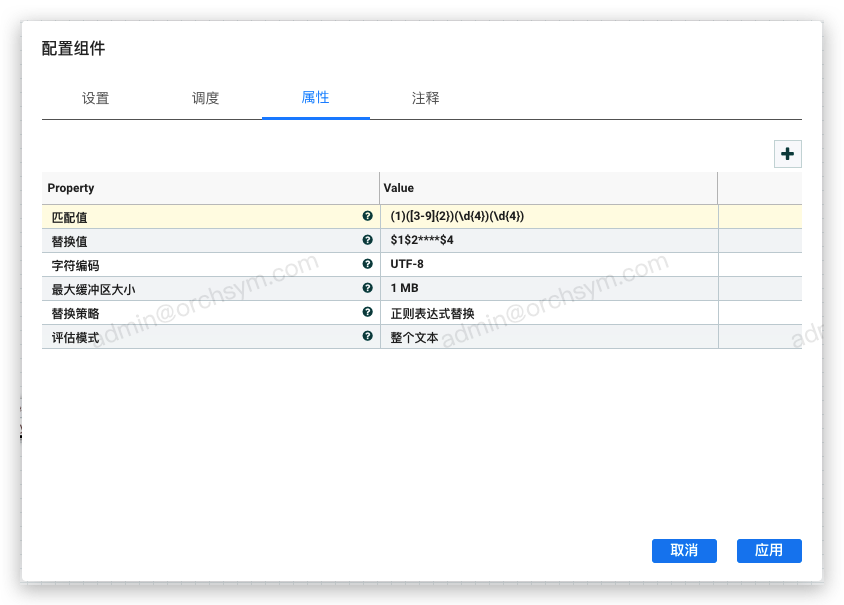
匹配值部分通过正则表达式来进行约束,符合该正则表达式的数字认为是手机号,并且通过捕获组方式,将匹配的手机号数字分了组,保留1、2、4组,将第3组的4位数字换成了*号,最终经过组件处理后的输出数据如下:
{
"password": "123456",
"address": "北京市朝阳区",
"idCard": "360123202111111121",
"name": "张三",
"mobile": "159****6788",
"tel": "0571-28821110",
"job": {
"jobName": "研发",
"address": "北京市朝阳区东风德必园区K栋",
"company": "白山云",
"tel": "0571-28821110",
"position": [
"需求",
"开发",
"测试",
"上线"
],
"salary": 2000
},
"cardNo": "6227002020000101221",
"email": "zhangs12345@qq.com"
}
可以看到 mobile 字段已经被加密处理
2. 文本前置和文本后置:JSON对象转数组
如果简单的想将单个 JSON 对象转换成包含单个对象的 JSON 数组,那么可以通过 ReplaceText 组件直接实现。
这里只是为了演示,实际场景中应该是多个JSON对象转成数组,应该用其他方式实现
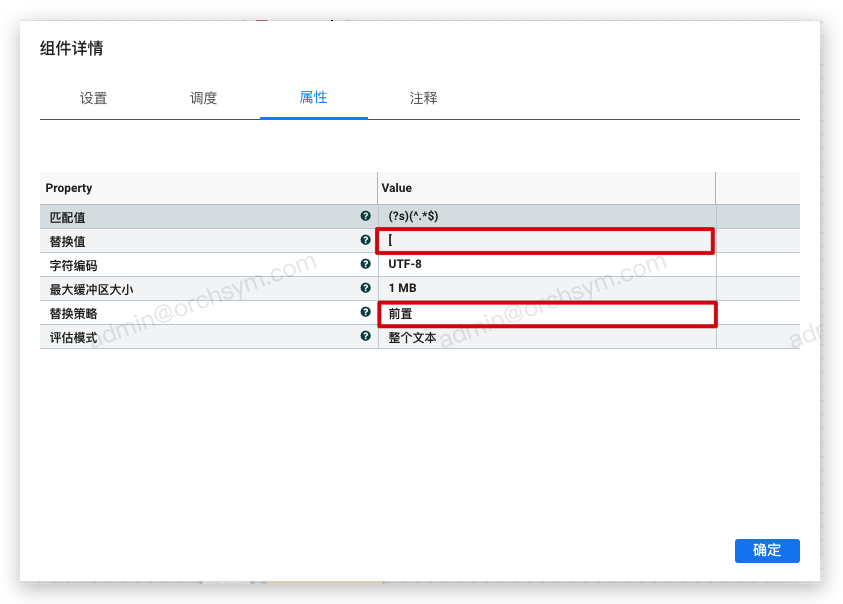
通过2次 ReplaceText 组件操作,一次前置,一次后置,最终转换后的数据如下:
[{
"password": "123456",
"address": "北京市朝阳区",
"idCard": "360123202111111121",
"name": "张三",
"mobile": "15928826788",
"tel": "0571-28821110",
"job": {
"jobName": "研发",
"address": "北京市朝阳区东风德必园区K栋",
"company": "白山云",
"tel": "0571-28821110",
"position": [
"需求",
"开发",
"测试",
"上线"
],
"salary": 2000
},
"cardNo": "6227002020000101221",
"email": "zhangs12345@qq.com"
}]
3. 文字替换:替换流文件内容(检索匹配值)
选择文字替换策略时,匹配值选项指定的内容与流文件内容会以文本匹配的形式进行匹配替换:
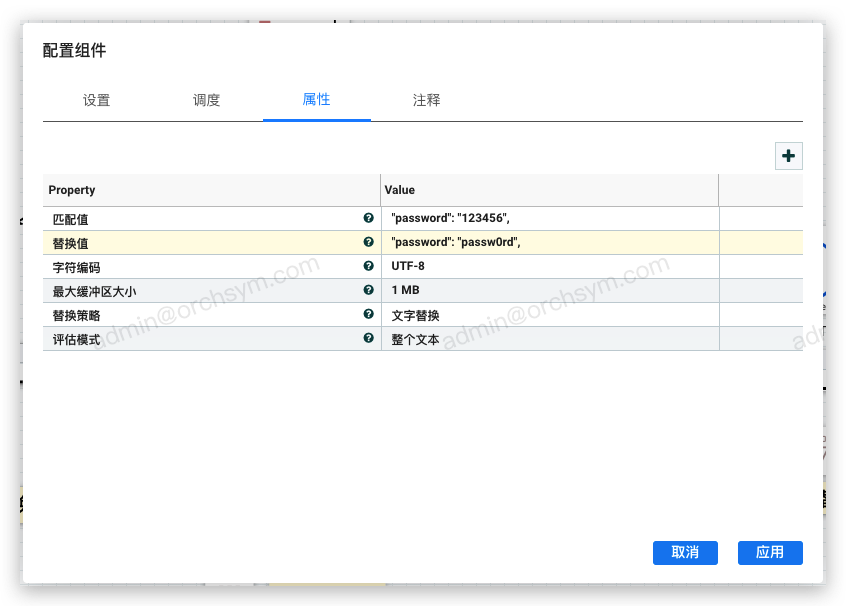
比如这里将 "password": "123456",修改为 "password": "passw0rd", 如果检索到匹配值选项对应的文本内容,会进行替换;如果没有检索到,则不会对流文件内容进行任何处理,最终ReplaceText组件处理后的输出结果为:
{
"password": "passw0rd",
"address": "北京市朝阳区",
"idCard": "360123202111111121",
"name": "张三",
"mobile": "15928826788",
"tel": "0571-28821110",
"job": {
"jobName": "研发",
"address": "北京市朝阳区东风德必园区K栋",
"company": "白山云",
"tel": "0571-28821110",
"position": [
"需求",
"开发",
"测试",
"上线"
],
"salary": 2000
},
"cardNo": "6227002020000101221",
"email": "zhangs12345@qq.com"
}
4. 始终替换:替换流文件内容(忽略匹配值选项)
始终替换策略和文字替换策略本质是一样的,都是用替换值选项指定的内容去替换掉流文件内容。两个策略不一样的地方在于,始终替换策略会直接替换,不管流文件内容是什么;文字替换策略是符合匹配值选项指定的部分内容才会替换。
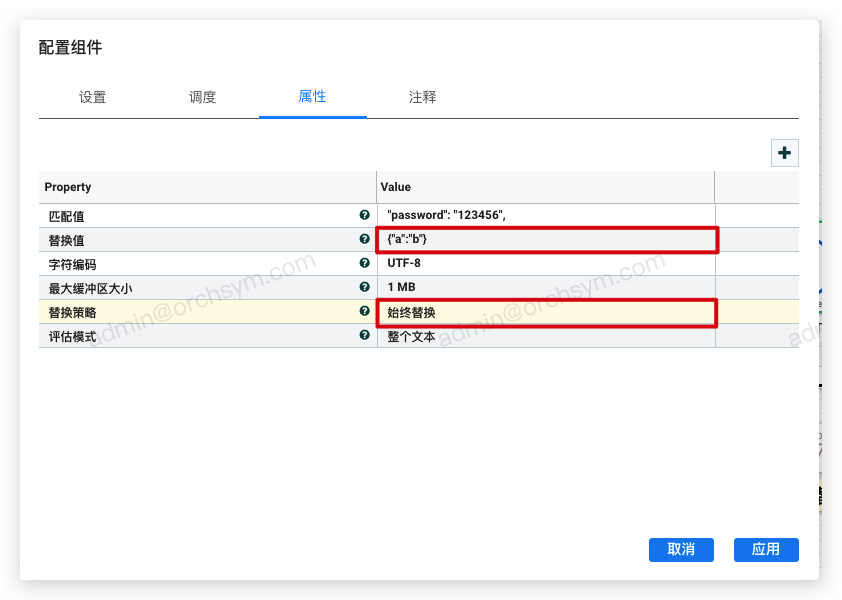
始终替换策略下,
匹配值选项会被忽略
最终ReplaceText组件处理后的输出结果为:
{"a":"b"}
5. 表达式函数:正则捕获组使用表达式函数
上面几个示例介绍了如何使用 ReplaceText 来修改流文件内容数据。上面是几个简单、直观的示例,但是,如果需要在匹配的数据上进行更加复杂的数据处理,比如对匹配到的密码字段进行 Base64 编码处理,就需要用到表达式函数。假设有以下数据:
{
"password": "123456",
"address": "北京市朝阳区",
"idCard": "360123202111111121",
"name": "张三",
"mobile": "15928826788",
"tel": "0571-28821110",
"job": {
"jobName": "研发",
"address": "北京市朝阳区东风德必园区K栋",
"company": "白山云",
"tel": "0571-28821110",
"position": [
"需求",
"开发",
"测试",
"上线"
],
"salary": 2000
},
"cardNo": "6227002020000101221",
"email": "zhangs12345@qq.com"
}
现在的需求是password字段进行 Base64 编码 处理,那么可以通过以下配置方式实现:
匹配值: "password": (.*)
替换值: "password": "${'$1':base64Encode()}",
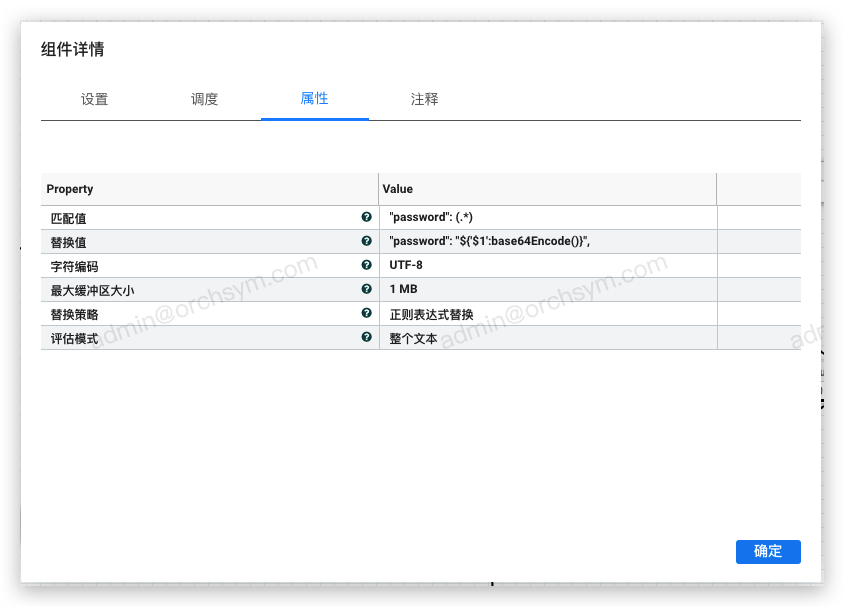
匹配值部分,通过正则表达式来匹配 password 字段的值,通过捕获组的方式,将值部分捕获;替换值是,直接通过捕获组 $1 来读取password 字段的值,然后通过调用表达式函数,对捕获到的数据进行编码处理,最终ReplaceText组件处理后的输出结果为:
{
"password": "IjEyMzQ1NiIs",
"address": "北京市朝阳区",
"idCard": "360123202111111121",
"name": "张三",
"mobile": "15928826788",
"tel": "0571-28821110",
"job": {
"jobName": "研发",
"address": "北京市朝阳区东风德必园区K栋",
"company": "白山云",
"tel": "0571-28821110",
"position": [
"需求",
"开发",
"测试",
"上线"
],
"salary": 2000
},
"cardNo": "6227002020000101221",
"email": "zhangs12345@qq.com"
}
五、注意事项
- 除非打算在流文件内容中匹配换行符,否则切勿使用
整个文本的评估模式。 - 确保为
最大缓冲区大小设置合理的限制(默认值 1MB 通常已经足够)。 - 尽可能避免在正则表达式中使用开销昂贵的表达式,例如
.*; 相反,只包含需要匹配的文本部分,不必匹配整行文本。 - 使用
$1、$2、$3等引用捕获组,以便将表达式函数应用于流文件的内容。 - 如果可以,优先选择基于Record的处理器,例如 UpdateRecord,而不是 ReplaceText,因为它比使用正则表达式更高效且更不易出错。
六、流程模板
下载后导入编排平台运行:
参见附件(请右键另存保存):ReplaceText